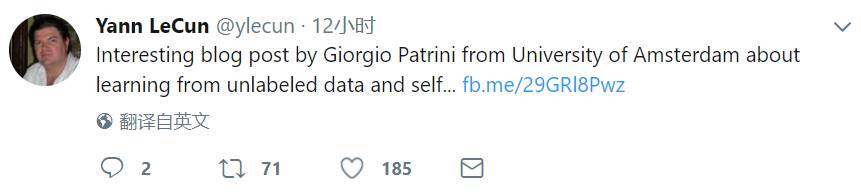
《Unsupervised learning by predicting the noise》这篇论文给出了一个很异乎寻常的答案,就是噪声。我认为这篇论文在今年的 ICML 大会上是最重要的研究之一。论文的构想如下:每一个样本都相当于超球面上的一个向量,向量标注了数据点在其上的位置。实际上,学习的过程就相当于将图像和随机向量匹配对应,通过在深度卷积网络里训练,并通过监督学习最小化损失函数。
我接下来的发现来自 Léon Bottou 一次极富启发性和争议性的报告 Looking for the missing signal (https://www.youtube.com/watch?v=DfJeaa--xO0&t=12s)(没错,本文作者偷了他的题目)发现的另外一半来自于他们的 WGAN,是关于因果关系的。但是在讨论之前,我们先回顾一下看看因果关系如何与我们的讨论联系起来。参见论文《Discovering Causal Signals in Images》。
现在我们可以将图像中物体和环境通过因果或者非因果关系联系起来。这样导致的结果是,举例来说,「拥有最高非因果分数的特征比起拥有最高因果分数的特征,表现出更高的物体分数。」通过实验性的证实这个猜想,结果暗示了,图像中的因果性实际上是指物体和背景之间的差异。这个结果展现了其开辟新的研究领域的潜力,理论上,当数据的分布改变的时候,一个更好的探测因果方向的算法应该能更好的提取和学习特征。参见论文:《Causal inference using invariant prediction: identification and confidence intervals》、《Causal Effect Inference with Deep Latent-Variable Models》。
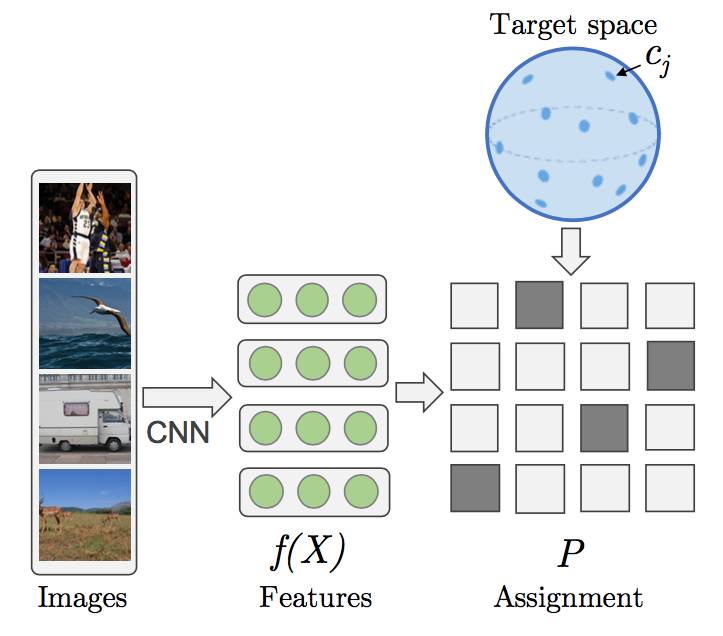
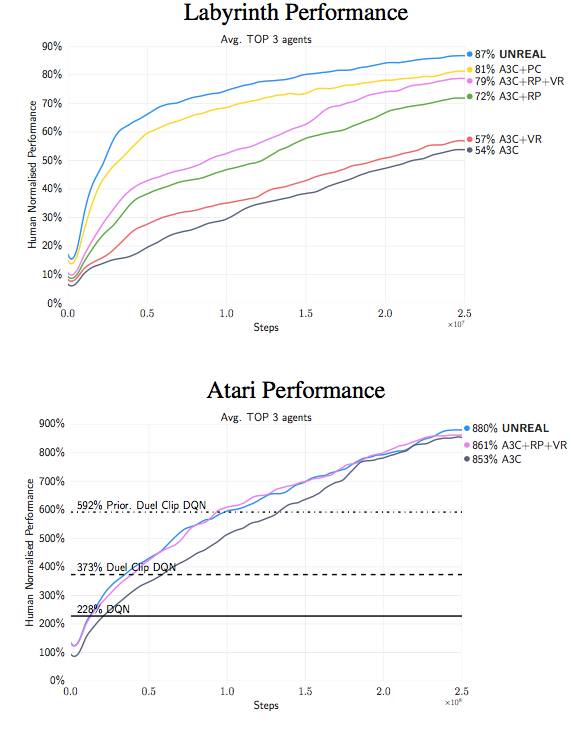
通过非对称自我模拟的内在动机形成和无意识学习:论文《Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play》。最后我想强调的一篇论文是强化学习中关于辅助任务的想法。不过,关键是,相比明确的扭曲目标函数,智能体被训练完成完整的自我模拟,在确切的范围内可以自动生成更简单的任务。
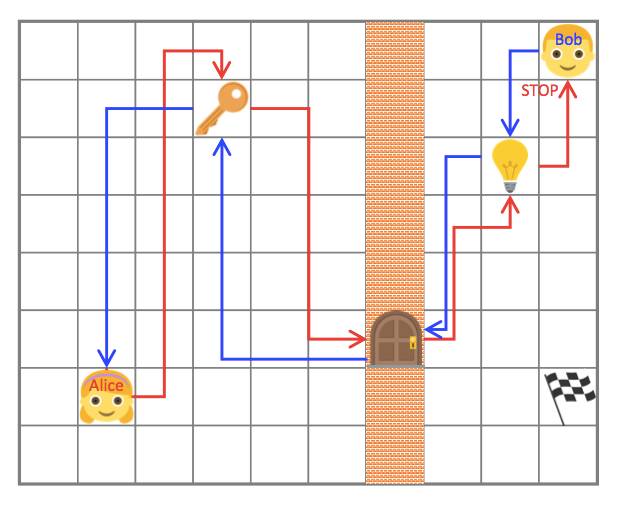
自我模拟的最初形态是将智能体分离成「两个独立的意识」而建立的,分别称作 Alice 和 Bob。作者假定自我模拟中环境是(几乎)可逆的或者是可以重置到初始状态的。在这个案例中,Alice 执行了一个任务然后叫 Bob 也做同样的事,即根据 Alice 结束任务时的位置,到达世界中的同一个可观测状态。例如,Alice 可以走动然后捡起一把钥匙,打开一扇门,关掉灯然后停在一个确切的位置;Bob 必须跟随 Alice 做同样事情然后和 Alice 停在同一个位置。最后,可以想象,这个简单环境的根本任务是在灯打开的时候在房间里拿到旗子。
那些任务由 Alice 设定并强迫 Bob 学会与环境互动。Alice 和 Bob 都有明确的奖励函数。Bob 必须将完成任务的时间最小化,而在 Bob 完成了任务的前提下又更费时的时候,Alice 反而能得到更多的奖励。这些决策的相互作用使他们「自动构建起探索的过程」。再次提醒,这是特征学习的自我模拟的另一种实现的想法。
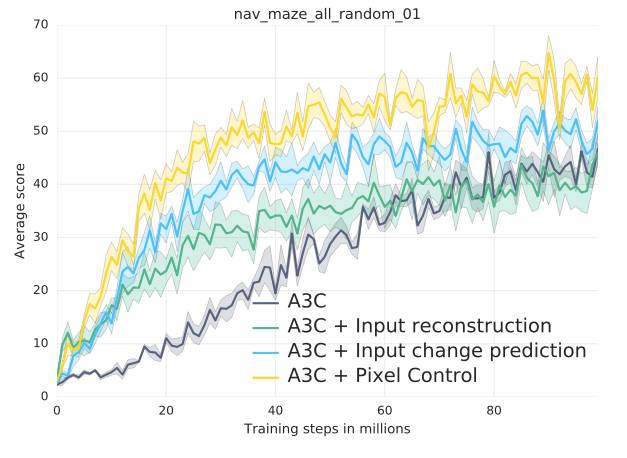
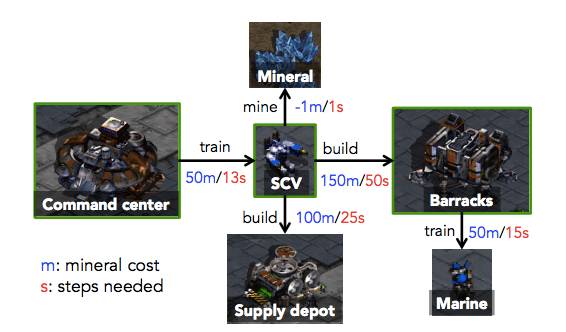
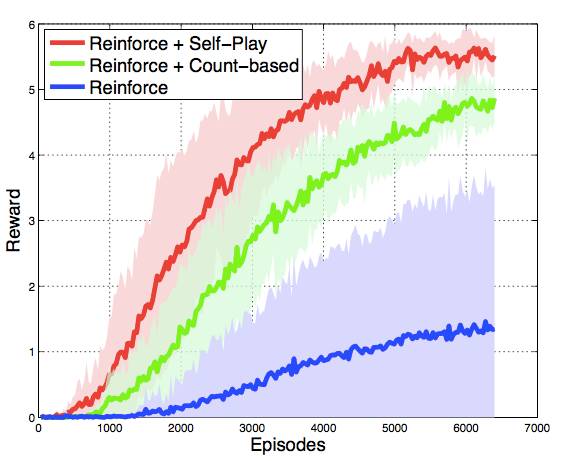
虽然完全匹配真实游戏中的状态几乎是不可能的,Bob 成功与否只取决于游戏中的全局状态,其中包括了每种单位的编号(包含建筑),以及矿物资源的累积程度。因此 Bob 的目标是在自我模拟中,完成 Alice 在最短时间内能建造的机枪兵数量和累积矿物的数量。在这个方案中,自我模拟确实有助于加快强化学习,并且在收敛行为上表现上,比起强化学习 一个更简单的决策预训练的基线方法的组合,要更好: